
Abstract
Artificial General Intelligence is the idea that someday an hypothetical agent will arisefrom artificial intelligence (AI) progresses, and will surpass by far the brightest and mostgifted human minds. This idea has been around since the early development of AI. Sincethen, scenarios on how such AI may behave towards humans have been the subject of manyfictional and research works. This paper analyzes the current state of artificial intelligenceprogresses, and how the current AI race with the ever faster release of impressive new AImethods (that can deceive humans, outperform them at tasks we thought impossible totackle by AI a mere decade ago, and that disrupt the job market) have raised concernsthat Artificial General Intelligence (AGI) might be coming faster that we thought. Inparticular, we focus on 3 specific families of modern AIs to develop the idea that deep neuralnetworks, which are the current backbone of nearly all artificial intelligence methods, arepoor candidates for any AGI to arise due to their many limitations, and therefore that anythreat coming from the recent AI race does not lie in AGI but in the limitations, uses, andlack of regulations of our current models and algorithms.
1. Introduction: AI Race and the Possibility of AGI
Artificial Intelligence (AI) has become an increasingly prominent field of research and de-velopment over the past few decades. In recent years, the development of AI has beenaccelerating, with more and more resources being devoted to the creation of increasinglysophisticated and capable AI systems that are now quickly released to the public and notcontained to science and research activities anymore. In particular, the recent public re-lease oflarge language models(LLMs) algorithms (Wei et al., 2022a; Bowman, 2023) basedon GPT-3.5 (Brown et al., 2020), GPT-4 (OpenAI, 2023) and LLaMa (MetaAI, 2023) hastaken the world by storm due to how we perceive that these methods are quickly progress-ing towards human-like conversation, writing and programming abilities, and how versatilethey are in the type of problems they can solve. This is particularly striking for severalmodels based on GPT-4 (Bubeck et al., 2023), such as Auto-GPT (Xaio, 2023), that can docomplex conversation and programming tasks without much human intervention by simplydirecting instances of itself. Due to their coding abilities, their relative autonomy, and theirapparently increasing intelligence, there are more and more claims that, without built-in orproprietary constraints, such programs could at some point modify and improve their ownsource code and reach the so called singularity (Vinge, 1993; Shanahan, 2015).
Sublime
With more and more countries being in an AI arm race (Berg, 2023; Naughton, 2023),companies competing and racing to be the one with the next most disruptive and trans-formative AI system (Armstrong et al., 2016; Bostrom, 2017), or simply seeking to turntheir idle data into assets (PwC, 2017), as well as eccentric billionaires also joining the raceto develop their own version of those sophisticated tools to subdue their rivals (Lee, 2018;Castro et al., 2019), there is a growing concern (Maslej et al., 2023; Reich, 2023) amongscientists, policymakers, and the public about the potential consequences of the so-calledAI race(Han et al., 2020) and the role it may play in the emergence of AGI (Xiang, 2023).AGI is an hypothetical superintelligent agent that could perform any intellectual taskthat a human being can, and do it faster and better due to its artificial nature. In otherwords,
AGI could potentially surpass human intelligence in every way, from problem-solvingto creativity. The fear of AGI mostly arises from the fact that such a system could becapable of self-improvement, leading to an exponential increase in its intelligence. Thiscould potentially lead to an AI system that is far more intelligent than any human being,which in the general public conjures Hollywoodian scenarios of AGI that would completelyescape our control, leaving mankind fate uncertain. Because our current AIs start to looklike (in some aspects) the early versions of those we saw in fictions in doomsday scenariosthat we imagined decades ago, they are generating unrealistic expectations and unnecessaryfears (Cave & Dihal, 2019).While there is no strict consensus, the following characteristics would be expected of anAGI (Legg & Hutter, 2007; Lake et al., 2017; Bubeck et al., 2023):It would need to begeneral:
It could perform a wide range of intellectual tasks. Thisgoes in opposition with the vast majority of current AI which are limited to a singleor a handful of tasks.
It would beadaptable: It would learn and adapt to new situations and tasks, ratherthan be limited to what it is pre-programmed for.
It would becreative: AGI would need to be capable of generating new ideas andsolutions, rather than simply following pre-existing rules or patterns
It would havecommon senseandbasic reasoningabilities: It would need to be ableto reason about the world in a way that reflects common sense understanding, ratherthan relying solely on hard statistical patterns or logical rules.
It would needlong term memory: By long term memory, we do not mean rememberingdata learned a long time ago, but that AGI should remember problems, tasks, stepsor solutions that is was previously presented with, so that it doesn’t make the samemistakes several times and has someplanning capabilities.
Optionally,self-awarenessandconsciousnessare often discussed as required proper-ties of AGI. However, it is unclear how to assess them for a computer program, nor ifit is truly needed for intelligence.
Due to several recent algorithms edging closer to one or several of the previously de-scribed properties, both the claim that we are getting closer to AGI (Bubeck et al., 2023)and the fear of what may happen are rising again.
The AI Race: Why Current NN based Architectures are a Poor Basis for AGI
In this paper, we will review several of these recent and impressive AI algorithms, howthey have evolved through time, and their architecture. In particular, we will focus on3 categories of AIs: AIs developed to play games (checkers, go, Chess and Starcraft II),generative AIs (for artistic or deep fake applications), and personal assistant AIs built withlarge language models to chat with humans. Since they are all based on deep neural networktechnology, we will assess what this implies in terms of capacities but also limitations thatsuch algorithms will have in the future. In particular, we will focus on reminding how thesemethods work and interface with the real world. By doing so, we will defend the argumentthat current deep learning based methods (that is, all current trendy AI methods) are poorcandidates for developing AGI due to the inherent nature and many bottlenecks of thistechnology when it comes to learning or intelligence in general.
Our argument, will be a direct complement to the recent Microsoft paper on GPT-4showing sparks of AGI(Bubeck et al., 2023), but not limited to the scope of LLMs modeland with an additional architecture oriented perspective to the limits of current AI systems.We will finally develop on the idea that while they are not likely to become AGI, it does notmean that these algorithms or their future versions are harmless should their developmentbe left unchecked in the current AI race.
Our paper is organized as follows: First, we will discuss some of the state-of-the-artAI that were introduced to the public in different fields, what they use in terms of deeplearning techniques, and where they lie in terms of intelligence. We will follow with asection discussing the core architecture, principles and the limits of neural network-basedmodels with examples from the two previous sections. Finally, we conclude our paper withthe actual questions and dangers of neural network based AI systems and a discussionsummarizing the different elements presented in this work.
2. AI has evolved fast and far: An Overview of the Current mostImpressive AI Systems
In this section, we will present some of the most impressive AI systems to date in theirrespective fields and how they have evolved. We have sorted them in 3 categories:
AIs for games,
Generative AIs used for deep fakes or artistic purposes,
Personal assistant AIs based on large language models.
Please note that these categories are arbitrary and were chosen for readability purposes andto better show their evolution in different domains of application. However, as we can seefrom Figure 1, they all come from the same family tree of methods and are overlappingin terms of technologies: For instance, the generative models (Goodfellow et al., 2014),which are the core of deep fakes and artistic AI, are also used by large language modelswhich power the latest personal assistant AIs, and the adversarial learning process (Szegedyet al., 2014; Goodfellow et al., 2015) used by these methods is also used by the latest AIsfor games. Finally, the vast majority of recent methods from all 3 categories all use deepneural network architectures
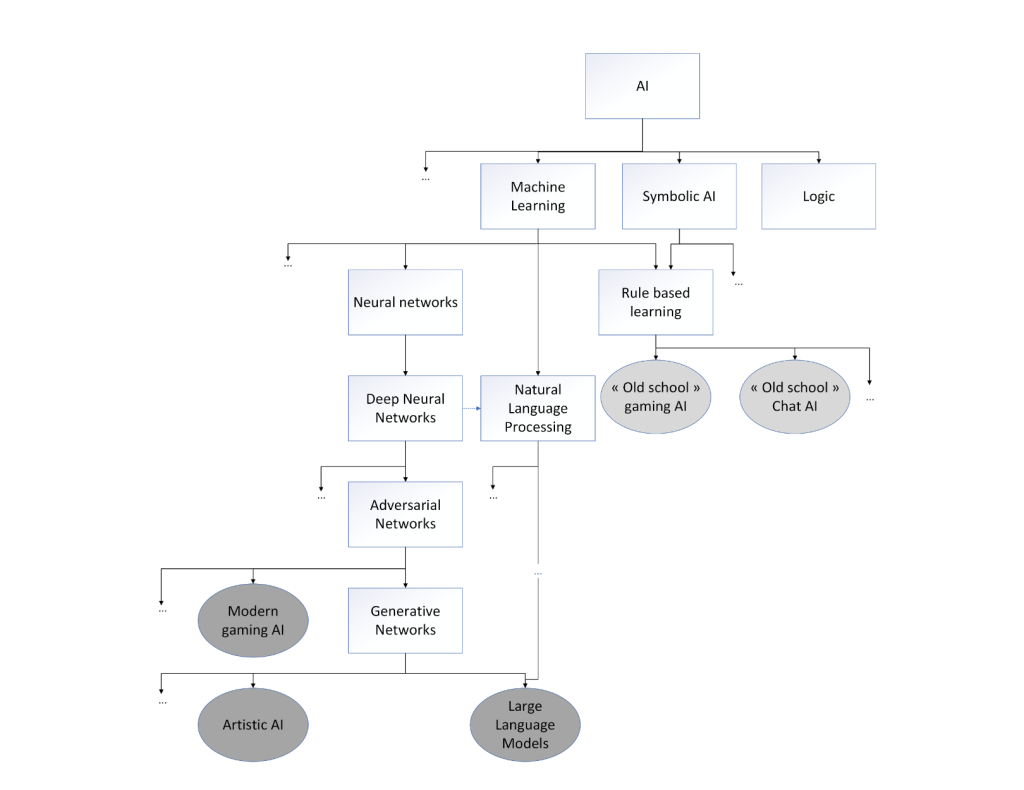
Figure 1: Simplified family tree of the AI systems presented in this paper. The families ofmethods discussed in this paper are displayed in grey. As we can see, moderngaming AIs, artistic AI as well as large language models all belong to the Deepneural network branch and don’t have symbolic and rule-based AI in their an-cestors. On the other hand, “old school” yet successful systems belong to thesymbolic AI branch.
2.1 AIs for Games
AIs for games are the ones that speak the most for a broad non-scientific audience, and theyalso have been around for the longest, which is why we chose to start with them. Regardlessof whether they were developed for traditional board games or for videos games, more orless advanced programs have been around since the 1950s to enable people to play alone,or rather against a machine:Christopher StracheyandDietrich Prinzwrote computerprograms able to play checkers and Chess respectively as early as 1951 at the Universityof Manchester. It is thenArthur Samuel’s checkers program, developed in the early 60sthat was the first to be good enough to challenge an amateur player (Schaeffer, 2014). Asfor one player video games against adversaries, they started to appear with single player games in the late 1960s and truly took off starting with 1978 “space invaders”. However,the first occurrence of a computer program being better than human champions (withoutcheating) occurred with IBM Deep Blue Chess playing computer (IBM, 2008) who beatGarry Kasparovin 1997.
While Deep Blue appears to be the first great AI of our era, it is actually not a properartificial intelligence program: It was an expert system that uses rules and logic, and had thecapability of evaluating 200 million positions per second to search for the best next possiblemove. Deep Blue was trained using 700000 grand master games and by storing most ofthe possible Chess ending with 6 pieces, and all of them with 5 pieces or less. Using thishuge database as a starting point, Deep Blue relied on alpha-beta pruning (Pearl, 1982) -analgorithm to make tree exploration more efficient- and its paralleled computation power tobrowse at high speed through the tree of possible moves to find the best one. In other words,Deep Blue was not really an artificial intelligence, but rather a brute force algorithm assistedby an efficient alpha-beta pruning method and huge hardware capabilities for its time. Still,Deep Blue has been a solid inspiration for later Chess playing AI such as Stockfish (Maharajet al., 2022), which was also based on a pruning algorithm before being hybridized withneural networks, before this type of model culminated for Chess with engines such as LeelaChess Zero (a Chess adapted version of AlphaGO Zero that we will discuss in the nextparagraph) (Silver et al., 2018). In Figure 1, all these models belong to the“old school”gaming AIbranch that descends from symbolic AI and rule-based learning. This type ofmodel has the huge advantage that it is explainable, and therefore we can understand whythe algorithm chooses certain moves over others.
As we show in Table 1, with an average of only 20 to 40 moves per game and a maximumtree depth of possible moves estimated around 120, for the game of Chess alpha-beta pruningthrough the tree of possibilities and memorizing a large number of game to cover mostpossibilities remained a valid option. This is not the case however for the game of Gowith its 19×19 board, 150 to 350 moves per game, and a tree depth as well as number ofpossible positions which are intractable. For this reason, the game of Go was long consideredimpossible to Master by traditional AIs that would simply try to brute-force through anintractable tree of possible moves. For the first time, a really smart computer program wasneeded, one that could plan its next move based not only on the branch most likely to leadto victory (which is impossible to assess given the depth of a Go game tree) but also basedon the current situation and how to make the best of it.
To answer these new challenges, DeepMind technologies (a subdivision of Google) de-veloped AlphaGo, the first AI able to play Go at high level and defeat world championsby combining neural networks and tree search (Silver et al., 2016). In its 2016 versionthat first beat World championLee Sedol, AlphaGo relied on this hybridization principlesbetween a deep neural network and Monte Carlo Tree search. The main prowess resultedin training the neural network to help predict which branches of the tree (and consequentlywhich moves) where the most interesting, without being able to browse to the full depth ofsaid tree. AlphaGo and its successor can do so efficiently all the while being able to guesstheir likelihood of ultimately winning the game after each move. For its training, AlphaGorequired a human database of 30 million of Go moves from 160000 games to attain a decentlevel, and was then further trained using reinforcement learning by playing against itself to further increase its skills. Unlike all previous AI for board games, AlphaGo did not use anydatabase of moves to play once the learning phase was over.
AlphaGo’s successor by the same team,AlphaGo Zero, was an even more impressivecase of artificial intelligence as it was trained without using any human games as reference,and only played against itself to figure out the best opening and moves (Silver et al., 2017).The development team reported that it took it approximately 15 million games againstitself in a total of 3 days to reach a decent level, and 40 days and approximately further200 million games against itself to be uncontested by both humans and earlier AI programsplaying Go. It is because of its “self-training” abilities over such an enormous space ofpossibilities that AlphaGo Zero was seen as a major break through in AI. Furthermore,while the original AlphaGo was considered conservative in the way it played, this was notthe case for AlphaGo Zero: it is also this “self-training” ability which led it to try movesand innovate during Go games in ways that humans would have never considered before. Itwas therefore able to surprise even the best humans champions due to the never seen beforenature of some of its moves. Obviously, very much like Deep Blue in its time, all iterationsof AlphaGo were supported by huge hardware capabilities, especially for the training phaseof the neural network. In a way, we could say that while in the case of Deep Blue hardwarewas used to brute force a tree exploring algorithm, for AlphaGo Zero and its successor, theraw computation power was used to play a number of games so huge that the algorithmwould self-train efficiently. Still, this shift in the use of computing power for modern AIproved useful as the technique used to train AlphaGo Zero was successfully reapplied toadapt it to the game of Chess and shogi (Silver et al., 2016), but also for protein foldingproblems (Heaven, 2020).
Moving to a new challenge, after AlphaGo Zero, the same DeepMind team turned toStarcraft II, an online real time strategy game by Blizzard Entertainement, as their newchallenge to tackle with artificial Intelligence. Compared with Chess and Go, as can be seenin Table 1 the game of Starcraft II constitute a major challenge step up in the followingways:
If we consider Starcraft II as a board game (which it is not), all games are playedover maps that are more than 128×128 in size, which is way bigger than the 8×8 ofChess, or the 19×19 of Go.
If you consider the number of mouse or keyboard actions as reference, an averageStarcraft II game requires 700 to 3600 actions, which is a ten fold increase comparedwith Go.
As a consequence of both the map size and number of actions, the number of possi-bilities and depth of a Starcraft II decision tree are considered to be infinite, which isalso a step up compared with Go.
While Chess and Go have time limitations, Starcraft II is not turn-by-turn and isplayed in real time.
Starcraft II is way more complex than Chess or Go in the sense that a game requiresyou to do the following in parallel: develop your economy and gather resources, buildunits that will counter your opponent units (think rock-paper-scissor, but a lot more complicated), control and send your units out to see what your opponent is doing,destroy his economy as well as his units.
Battles between units go beyond which units are effective or not against another asunit micro-management is required in real time: for instance using units skills andspells at the right moments and places, but also moving and keeping damaged orfragile units in the back of your army whilst keeping tanky ones at the front.
Starcraft II hasfog of war, which means that unlike Chess and Go, you can’t see whatyour opponent is doing unless you send troops out to see what is going on.
From this description it is easy to see that to be good at this game without cheating (nofog of war, more powerful units, increased resources, etc.) an AI would need to have manyskills that resemble what would be needed for an AGI: planning capabilities, memory ofwhat happened a few moments ago, real time response abilities, and creativity.
Due to the large exploration space for a game like Starcraft II, a full self-training was notpossible, and AlphaStar was pre-trained using a database of 65000 games to learn the verybasic moves and some basic strategies. It is only then that it used the same self-trainingability by playing against itself to refine its strategies. This reinforcement learning phasealso included a phase against so-calledexploiter agentswhose purpose was to tackle themain agent on its own weaknesses so that it could improve.
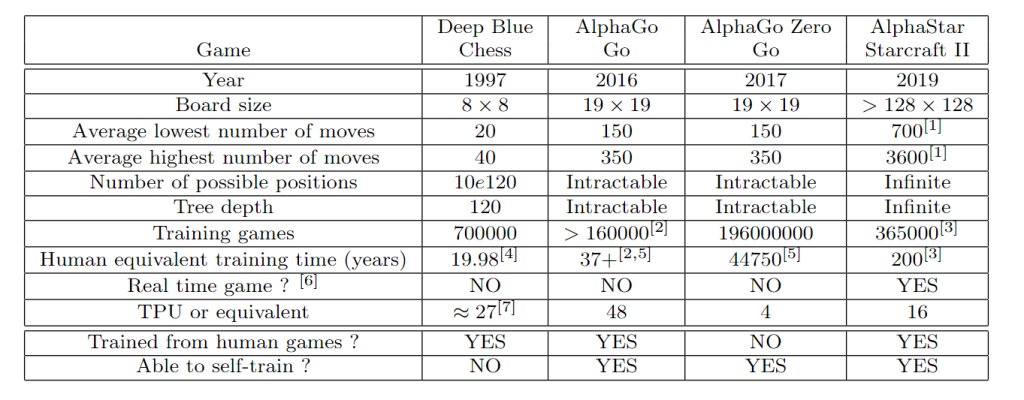
Table 1: Comparison of 3 famous gaming algorithms in terms of complexity of their finalapplication and their models: [1] computed on the basis of 70 to 120 actionsper minutes for games lasting 10 to 30 minutes; [2] The number of self-traininggames is unknown; [3] The original algorithm was trained from 1000 pro games,but DeepMind declared 200 years equivalent of human training, and we estimatethat pro-gamers play on average 5 games a day; [4] Assuming 15min games; [5]Counting 2h per game on average; [6] While Chess and Go are played with timelimitations, Starcraft II requires real time actions and responses; [7] Estimatedusing 0.42 GFLOPs for a TPUv3, knowing that Deep Blue was estimated at 11.38GFLOPs.
Very much like for AlphaGo, world top Starcraft II players that faced AlphaStar weresurprised to see the algorithm using strategies that had never before been seen in humangames. Also like for the game of Go, the AI quickly proved to be able to defeat any humanplayer. Furthermore, due to the fact that it was initially unlimited in the number of actionsper second it could make, it was nearly impossible for a human to beat AlphaStar’s unitmicro-management, as humans are limited by their physical abilities as well as their use ofmouse and keyboard, and can’t sustain a very high number of actions per minutes for long(typically 60 to 120 actions per minute at best). For this reason, AlphaStar was cappedin terms of number of actions per minutes it could make, but still proved better thanhuman players. However, it is worth mentioning that unlike for the game of Go, there wereseveral instances where AlphaStar showed its limits by being unable to assess a situationit had probably never seen before or had an erratic play style that made no sense at all:For instance, Starcraft II uses a wide array of maps (boards) that are all different and 3different races. AlphaStar was initially able to play a single race and was limited to thesets of maps it knew, and was unable to adapt to others. While switching race can provechallenging for beginner humans players, it does not result in “nothing happening”. Asfor map changing, it presents no problem at all for humans (even at very low level) andshows that humans have an adaptability that it does not have. Finally, in some matches,AlphaStar proved unable to properly assess whether it was losing or winning, which resultedin erratic behavior very similar to what could often be seen from an “old school” AI goingout of its decision tree.
It is worth mentioning that while attempts have been made at reproducing AlphaStar-like performances with smaller networks and less hardware (Liu et al., 2022), such feats areso far limited to companies with huge research departments and computation power.
2.2 Generative or “Artistic” AIs
In this paper, we callartistic AIthe different algorithms that have been released with theability to create artistic or realistic images of videos on different subjects. This type of AIfirst appeared with the neural network called Inception (Szegedy et al., 2015) whose originalgoal was to detect objects in images, but was later used as a reference to understand howconvolutional neural networks worked, and in particular their different convolution layers.Using the Inception network, a team from Google proposed theDeepDreamsoftware, aprogram generating psychedelic and dream like images. While still used to detect elementsof interest in images (mostly faces), DeepDream uses a reverse process compared withnormal detection network and will twist and adjust the image to look like something elseby giving an output neuron more importance than it should have (a cat face instead ofa human face for exemple) and will then proceed to alter the original image via gradientdescent so that it matches with the purposefully wrongly activated neurons. This results invery strange images reminiscent of what can be experienced by LSD users, which led somescientist to believe that convolutional neural network share common architecture with thevisual cortex of humans (Schartner & Timmermann, 2020).
While DeepDream was the first neural network to generate false images, it is laternetworks based on generative adversarial networks that really became known to the publicaudience for their ability to generate the so calleddeep fakes: images or videos artificially generated and for which it is very difficult to say whether it is a real picture, or somethinggenerated by an AI.
These deep fake networks use both the autoencoder principle (Hinton & Zemel, 1993;Kingma & Welling, 2014), (See next section and Figure 3 for details): the encoder finds alower space representation of a person or thing to modify. Once this is done, key featurescan easily be changed in the reduced feature space, and the decoder will proceed with thereconstruction of the modified (fake) image. Coupled with a generative adversarial network(Goodfellow et al., 2014) after the decoder, this technology has proven to be very powerful.The main principle of generative adversarial network is to have 2 networks following anoptimization process against one another:
The first network (the discriminator) is trained to detect real images or videos fromartificially generated ones.
The other network (called the generator) tries to generate images or videos that won’tbe detected as fake by the first network. It is optimized to make fakes that are moreand more difficult to detect.
These deep fakes can be used in all sorts of ways: adding, replacing or removing somethingor someone from an image, changing small or major details, generating a video of someonesaying a speech that never happened, building a full composition image of things that neverhappened (for example in image of the pope partying in Coachella), etc. Because of theadversarial training process, very realistic generators can be trained, and their generatedimages are impossible to tell from real ones.
While not a proof of general intelligence per se, these deep fake algorithms can generatefrom scratch very realistic images on demand by simply having a user describing what he orshe wants. It can mimic any style of photo, painting or art, and there is also the possibilityof using random parameters to generate images or videos. In any case, with the best ofthese generative algorithms, the output will be very realistic and unique, which can beinterpreted as a form of creativity.
2.3 Personal Assistant AIs
We will now move on to the last category of AI discussed in this paper, the so-called“assistant AI”. This category regroups all AIs models that were developed to interactwith humans with the goal of helping them: Personal home assistant such as Amazon’sAlexa, Google Home, Microsoft’s Cortana, and Apple’s Siri, the many chatbots developedfor support services, and obviously conversational AIs such as ChatGPT.
Conversation has always been considered a difficult task as it requires to both understanda question, and producing an answer that is accurate and understandable. AIs targeted atthis type of task therefore have to master language data, which have some very specificchallenges:
Words are more than simple data that can be hard encoded into binary vectors. Anefficient AI algorithm would have to learn (or at least use) a word embedding systemin which closely related and semantically similar words are similar enough in theembedding space. This is what Word2vec (Mikolov et al., 2013) does for instance.
Understanding language requires more than knowing a list of words and their semanticrelationships: it also entails a basic understanding of grammar in order to properlyunderstand a question, a prompt or a text: the tense of a verb, the presence ofnegations, and the grammatical role of some groups of words can completely changethe meaning of a sentence.
Most languages contain at least 80000 to 300000 words, which is a lot to learn, espe-cially if you add the semantic. Grammar also varies from one language to another,although there are some common basis.Specific idioms and second degree humor can make a sentence all the more difficultto understand.
All the reasons mentioned above have made assistant AI particularly difficult to develop,and it is only recently that the first effective assistant AIs have appeared. Indeed, beforethe generalization of neural networks to learn large corpuses and semantic relationships,most assistant AIs simply relied on the detection of a limited number of keywords andexpressions, and proposed pre-set answers accordingly. Most early chatbot fall under thiscategory and -very much like early gaming AIs- belong to the family ofSymbolic AIshownin Figure 1. Assistants such as Google Home or Alexa use neural networks to process thesounds they hear into instructions with words given to their algorithm. But the “reasoningpart” to interpret the instructions is similar the early chatbots and also belongs to thesymbolic AI branch to decide what to do or to answer.
As one can see, the main difficulty in natural language processing is not so much thedecision making or the generative process, it is to properly model the language to bothunderstand and answer questions. Once again, it is deep neural networks that broughtthe main advances in the field of natural language processing. Word2vec (Mikolov et al.,2013) is one of the first proposed word embedding system that accounts for word semanticin text data representation. It was more recently followed by BERT (Devlin et al., 2019),another embedding system relying on neural networks. The main difference between the2 technologies are the following: BERT allows several vector representation for the sameword, while Word2vec only has a 1-to-1 mapping. BERT can handle words that are outsidethe original vocabulary it was originally trained with, while on the other hand Word2veccannot do so. From Word2vec and BERT, the next main advance was large language models(LLMs) whose principle is to take as input a list of tokenized words using embedding (thequestion or prompt) and to output a probability distribution over the vocabulary known bythe system and which will be used to build an the answer. These systems are called “large”because they use billion of parameters and are trained over very large bases of vocabulary.With 340 million parameters and a corpus of 3.3 million words, BERT is considered tobe the first large language model, and is somewhat small compared to GPT-3 (175 billionparameters and 300 billion tokens), LLaMa (MetaAI, 2023) (65 billion parameters and 1.4trillion words) or GPT-4 (OpenAI, 2023) with more than a trillion parameters.
AI systems belonging to the LLM family have shown rapid and impressive progresses:With each new iteration or version, they act more and more human in the way theyinteract with people and can do casual conversation and have the apparent ability tosolve logic problems just as well as humans do.
They are fluent in a large number of human languages and can translate easily fromone language to another.
In addition to natural languages, many of these AIs now have programming ability.In terms of technology, these systems cover two main tasks:
Learning and embedding the large set of words or tokens that constitute their vocab-ulary. We have already discussed this difficulty and this is done by pre-training themon very large textual databases such as Wikipedia or GitHub.
Training the neural network to actually produce good quality answers based on analmost infinite possible number of prompts. This is done using a mix of self-supervisedlearning and reinforcement learning from both human and other AI instances. Thisis very similar to what we have seen for AlphaGoZero and AlphaStar, but applied tolanguage.
These systems have recently surprised the World with the ability of some of them tosuccessfully pass the Turing test (and successfully pretend to be human), the large panel oftasks they can do with efficiency, but also some very specific abilities that appear to havespontaneously emerged in some of them without being explicitly programmed.
Most recent LLMs also appear to have shown some reasoning abilities. However, thesereasoning abilities seem to be highly dependent on breaking-down or splitting the probleminto simpler sub-problems with intermediate prompts to increase the likelihood of a goodunderstanding by the neural network (Wei et al., 2022b; Zhou et al., 2023). Furthermore,it is very difficult to tell the difference between reasoning abilities and just having learnedon a database large enough to find the answer without any reasoning, and some researcherseven doubt that it can reason at all due to its lack of world model (Borji, 2023).
Indeed, it is worth mentioning that they have also shown limits, such as the so-calledhallucinationsin which these systems proposed with great certainty an answer to a givenquery which is not correct and sometimes has no real basis. A good example of suchhallucinations is ChatGPT proposing references of scientific papers that do not exist: thejournal exists, the authors have realistic names, the title seems to match the question askedto the algorithm and would be relevant for the journal, but the paper does not exist. Thisis due to the way these algorithms are programmed to find the most likely distribution intheir known vocabulary to propose an answer: with most questions, it just takes puttingthese words or tokens in a certain order to form a fine sentence and a correct answer. Doingso with pieces of a scientific paper and a matching journal will however most likely result insomething that does not exist. The same kind of strange behavior can happen when askingGPT-4 for the names of the feodal lords of some lesser-known villages, which it will answerby making up realistic names that are out of touch with the reality. There is another famousexample where GPT-3.5 was asked to remind the places of a series of past conferences, andit only returned the ones for odd years. When asked why he did not return the places foreven years, it answered that the conference did not take place on even years (which wasfalse). Likewise algorithms such as LaMDA (Thoppilan et al., 2022) have been confused byuser prompts asking if Yuri Gagarin went to the Moon (which the algorithm successfullyanswered no), before affirming that he brought back moon rocks that he got from the Moon.
These four examples show the limits of these systems which mimic intelligence but areactually mostly trying to give you the most likely answer, which is different from the truth.
Finally, we can also mention that some “spontaneous” behaviors of such AI may some-time be very inappropriate: Microsoft Bing AI has had a few bad experiences with chatbotsgoing horribly wrong: The Tay chatbot in 2016 was a first example of an AI that went nazivery quickly because it was fed with the wrong data by malicious users. And more recentlysome of their latest LLM AI also acted very creepy with some of their users by either fakingsentiments for them, or displaying downright hostility.
3. State of the Art AI Systems and their Deep Learning Limitations toEvolving AGI
In this section, we discuss the building blocks, architecture, and training methods of theneural networks that are at the heart of most modern AI systems nowadays. In particular,we explain how these common blocks used in all modern neural networks are defining thecapabilities and limitations of modern AI systems.
It is worth mentioning that the Deep Learning paradigm is very likely to remain thedominant AI technology for the decades to come, and that as such everything presented inthis section is valid for current AI systems and for most systems to come. Indeed, as shownin Figure 1, all breaking ground new AIs systems come from the same family descendingfrom Machine Learning, deep neural networks, adversarial networks, and more recentlygenerative networks.
The main implication of all these algorithms coming from the same families of methodsis that they have many things in common as they inherit the strengths, weaknesses andcore principles of the same methods.
3.1 Core Principles and Main Components of Deep Neural Networks
Artificial neural networks are a family of machine learning methods remotely inspired fromthe neurons in the brain, and whose earliest apparition in computer science was in the1960s with the first perceptron (Minsky & Papert, 1969) and the conceptualization ofbackpropagation for optimization purposes (Amari, 1967). The field then stagnated untilthe late 1980s with the first conceptualization of neural networks able to learn phonemes(Waibel et al., 1989), and the idea of convolutional neural networks inspired by the humanvisual cortex for image analysis and interpretation using artificial intelligence (LeCun et al.,1989; Rumelhart et al., 1986). The field then rose to popularity and emerged for the generalpublic in the early 2010s when GPU-based computation power became available and cheapenough to allow for larger and more sophisticated networks to emerge and be trained faster.
In Figure 2 we show the basic components of all neural networks. First, we have neuralunits which basically process a set of inputs which are multiplied by weights to be learned.Each unit also contains an internal activation function which will determine the outputbased on the weighted sum of the neural unit inputs. A neural network itself is made ofseveral layers containing such neural units. We distinguish between different types of layers:
Input layers which handle either raw input data, or outputs coming from earlierblocks of the networks, and transform them into something usable by the rest of the network. For instance, text data needs to be transformed into numerical vectors, andconvolutional layers are typically used with images to extract features at differentscales.
Figure 2: On the left: a basic neural unit with 3 weighted inputs. – On the right: a simplenetwork with an input layer, an output layer and a single neural layer in themiddle.
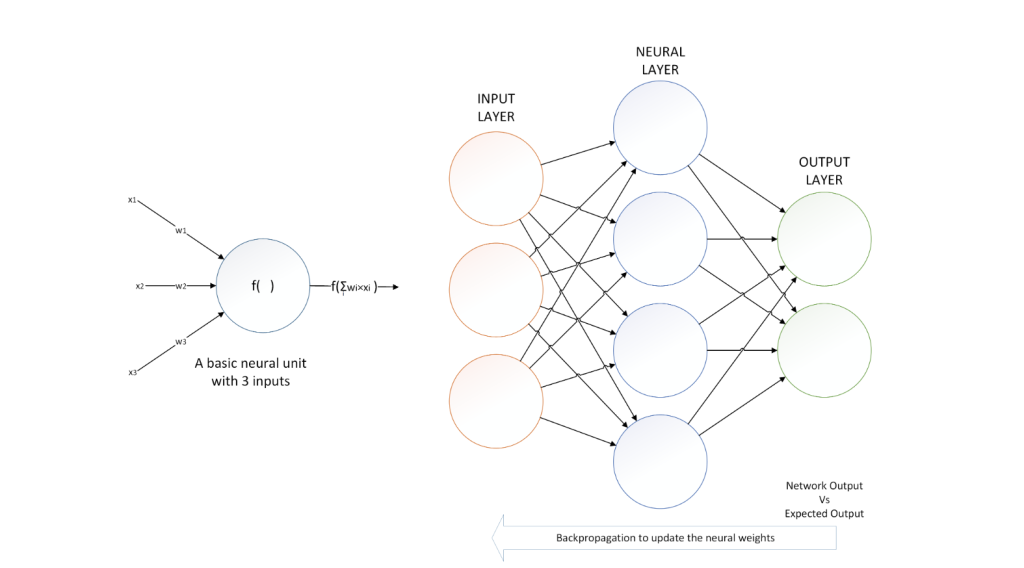
Neural layers between the input and the output. A typical neural network may countdozen or even thousands (hence the namedeepneural network) of these layers. Theyare used to find and disentangle complex representations of the input data.
Output layers which basically produce the answer of the network. This answer canbe in the form of a numerical vector, in which case these input layers are not verydifferent from typical neural units. However, in the case of a classification problem, itis typically expected that only one neuron from the output layer activates to decidewhich class is picked. This required specific activation functions and layer properties.
Neural networks are trained by means of gradient descent and back-propagation: Thenetworks (or blocks of the networks) are fed with multiple data which are going to runthrough the different layers and produce an output. This output is then compared withwhat was desired for the data that were fed, and the difference between the produced resultand the expected one is then back-propagated over the different layers of the network(s)so that the weights of the different units are adjusted to better match the expected result.It is worth mentioning that it is typical to use the root mean squared error, and not the raw difference, but that many different functions can be used depending on the task andproblem.
The goal of any neural network training is therefore to optimize an objective functionso that the network output becomes satisfying enough. A neural network such as theone shown in Figure 2 is very basic, but more complex neural networks follow the samebasic architecture with more layers, layers containing more units, and complex structurescontaining several sub-networks filling different functions.
3.2 Interfacing to the Real World and Extracting Features: A First Bottleneck
As we have seen with Figure 2, no matter their complexity or depth, all modern AI systemsinterface with the real world using an input and an output layer: Gaming AIs take thecurrent state of the game (or what they can see of it) as input, and output their next move.Personal assistant AIs take a written or oral prompt as input, and will output text or spokenanswer accordingly. Artistic AIs will take a set of parameters as input (type and size ofimage, a theme, or even a written description) and will output an image. Etc.
In most fiction works where an AI becomes aware and escapes, it starts to connect tosystems it was not supposed to connect to, and to do things it was not meant to. This isabsolutely impossible due to the fixed and static nature of the input and output interfacesof neural networks: The way neural networks are trained, which we have already brieflymentioned, and will detail more in the next sub-section, implies that the structure of theinput and output layers of any neural network is fixed. If it changes or is modified, thetraining must basically be done all over again from scratch.
Beyond simple interfacing limitations restricting the type of input and output, we canalso mention task specific interfacing limitations:
For instance, we have seen with text analysis tasks that there were different ways tofeed text data to an AI using Word2vec, BERT or large language models. In anycase, words or languages unknown to the algorithm would be difficult to understandfor any AI system as they would not be included in their original embedding system.
In image processing, where convolution layers are key to analyse an image, it doesnot take the same architecture to make a classification method to tell cats from dogs,and to analyse medical images: The convolution layers needed to search for specificelements at different scales would simply not be the same. It means in this case, thateven if an AI can interface to the 2 types of images, it may not have the right firstlayers to properly extract the relevant features.
Indeed, while we have simplified things by only discussing the first input layer as theonly interface with the external world for an AI, in truth while the first layers limit theformat of what can be accepted or not, there is a large number of the first layers whichis used to create the features that will later be processed by follow-up layers in a processknown asfeature extraction. This means that it is not only the format of the input layer,but also the format of the follow-up layers for feature extraction (e.g.: number and type ofconvolutions) which will determine what an AI efficiently interfaces to or not, even before ithas been trained. And once the training has been done for these feature extracting layers,it will narrow-down the possibilities even more.
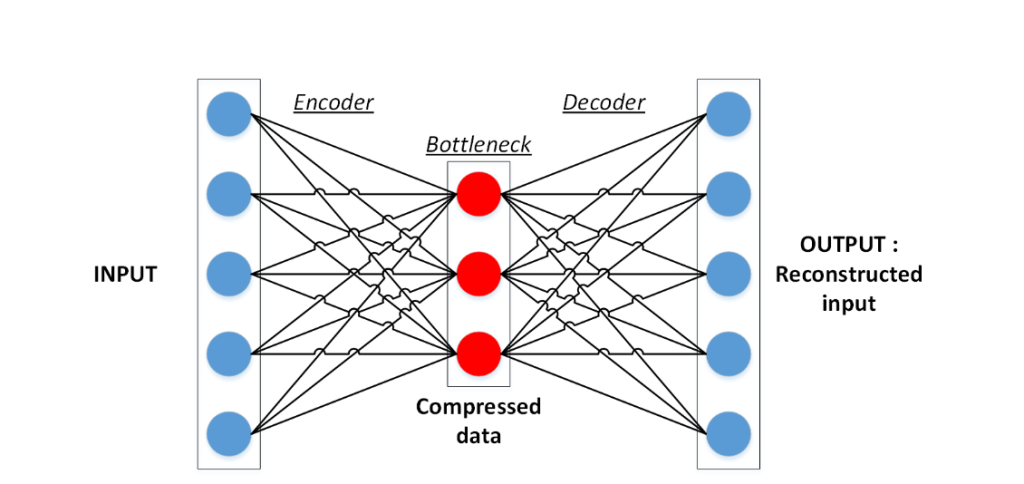
Figure 3: Example of a very basic autoencoder with a single hidden layer for compression.
In Figure 3, we show a typical autoencoder (AE) architecture (Hinton & Zemel, 1993),an unsupervised model used for feature extraction and whose principle is to train a networkto rebuild its input with a certain number of compression layers in between. The first partbefore the narrowest bottleneck layer is called the encoder, and the one from the bottleneckto the reconstructed output is the decoder. Once trained, the decoder part is discarded, andthe encoder can be kept and integrated into a larger neural network to transform originalinput data into better quality features. Yet, these “better quality features” would also befixed by the encoder architecture and training, and would be just as much a limitation as theinput layer. Once again, modifying them on the fly by adding or removing layers or neuronsis usually not an option. Variational autoencoders (VAEs) (Kingma & Welling, 2014) arean evolved form of autoencoders that maps the data into a latent space and inject whitegaussian noise between the latent space and the decoder to achieve more robust features.AEs and VAEs otherwise fit the same role of an unsupervised and self-supervised learningof the features.
To sum up these first sections on the limitations of current neural network based AI, wehave seen that the input and output layers, as well as feature extraction mechanisms whichenables these AIs to connect and interact with the outside worlds are limited and rigid.Furthermore, while we have simplified the problem to simple networks, in large AI systemswhich are made of very large deep and multi-component sub-networks, these structures areeverywhere in the network, which further limits its adaptability to efficiently interface withanything else than what it was designed for. Finally, while they are simpler, the outputpossibilities of such networks are perhaps even more limited in their format.
3.3 Limits of Objective Functions and Gradient-based Learning
Let us now discuss objective function based learning and gradient descent which are the twocore processes of Deep Learning algorithms. We will see how and why this type of learningis not compatible with the idea of AGI because of the way they restrict the types of tasksthat can be handled and are also currently incompatible with symbolic learning (they don’tbelong to the same AI branch as shown in Figure 1), a key feature of human-like learning.
The first obvious limit of objective based-learning is that some problems are not easyor convenient to model with an objective function: While it is somewhat simple to have a quality-based objective function for classification problems, or a reconstruction error tominimize for regression methods or autoencoders, it is more difficult for complex tasks. Forinstance, we mentioned earlier systems for games or personal assistants. In this case ratinga game move or a proposed answer and turning it into an objective function when the“best”move or answer are not known can be very challenging: Can we define such function whenthe best answers are not known ? And will it be possible to differentiate it and run agradient descent ?
This leads us to our second argument on the limitations of objective-based and gradientbased learning: it implies that the objective function must be differentiable. Indeed, thebackpropagation system used by deep learning methods requires that a derivative can befound in all layers, including the output one with the objective function. Furthermore, inthe case of a non-convex system (which is very often the case), convergence towards a localminimum rather than the optimal one is very likely with gradient-based learning, which isanother limitation.
Lastly, in its current form, both gradient-based learning, objective-function based learn-ing and the limited input interfaces are incompatible with symbolic-based learning whichencompasses structured data and is very useful to insert human-made rules into an AIsystem, but also to understand the decisions made by an AI. There is no place in gradient-based learning for hard rules (only for targeted examples to guide a system), and even lessfor complex structured data.
To sum up this subsection, objective function and gradient-based learning are limitingin two ways:
First, they cannot handled symbolic learning and structured data.
Finding the right and differentiable objective function can be challenging and is farfrom ideal: Even if one can be found, it will necessarily limit the type of tasks that anAI can process or not, and the risk of convergence towards a local optimum is alwaysa risk.
3.4 Learning Processes: More Bottlenecks
Let us now focus on the learning abilities of the current AI model. Our goal in this subsectionwill be to show that current AI models cannot lead to an explosion of generalized intelligenceable to answer or to know everything. To do so, we will use geometry to illustrate theproblem. Let us represent the space of problems an AI should be able to answer in itsspecific domain as a line in space:
If the problem is simple and finite, the line is also finite.
For complex problems such as generalized AI, the line is most likely infinite.The way most current AI methods based on deep learning work is that they are fed withexamples belonging to the space of possible problems (LeCun, 2018): If the examples areprovided with correct answers, then we are dealing withsupervised learning. If the algorithmis provided with just examples, left to explore and rewarded or penalized depending on itsanswer, then it isreinforcement learning. If the algorithm is only fed unlabeled examples and left on its own to provide answers in an unsupervised way, then we are dealing withunsupervised learning. The type of learning does not really matter for our analysis:
Before its training, the algorithm will have been provided with examples coveringsome of the considered problem space.
Once it is trained, the algorithm should be able to properly answer a certain amountof problems from the same space.
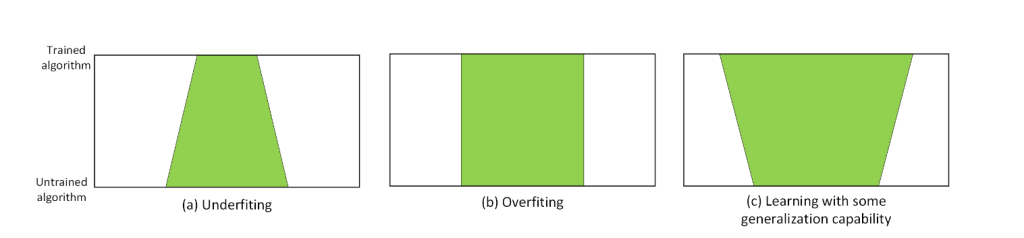
Figure 4: Geometric representation of underfiting, overfiting and fair generalization capa-bilities: The bottom and top lines of each rectangle are the problem space. Thelearning process from bottom to top is in green and show how much of the prob-lem space can properly be dealt with after the training based on the space coveredby the training examples.
There are 3 possibles outcomes to training an AI: In the first scenario, the AI underfitsand is only able to handle a much narrower number of cases (sometimes 0) than what wasfed to it during its training. This usually means, that the AI structure and models arenot complex enough to properly grasp the problem, or when the number of examples istoo small compared with the algorithm complexity. In the second scenario, the AI overfitsduring the learning process and will only be good at processing examples it has alreadyseen, but bad with anything else. This can be caused by all sorts of sampling issues withthe training examples, but also by an algorithm structure too complex compared with theproblem complexity. In the last scenario -which is the prefered one-, once it has been trainedthe AI algorithm can be effective at handling problems from a space larger than the set ofexamples it was fed. As hinted by the two previous scenarios, this can be achieved onlywith the right complexity for the AI algorithm relative to the problem, a sufficient numberof examples also relative to the complexity, and also a good enough sampling.These 3 scenarios are visually shown in Figure 4, where the bottom and top lines ofeach rectangle are the problem space and the learning process from bottom to top is shownin green. In this representation, and based on the previous explanations, we see that thelearning capability of an algorithm can be modeled as a functionL(CX, SX, CA, SA) whichproduces a result which will reflect on whether or not the algorithms will be able to tackledata beyond what it was fed:
This result will be negative if the algorithm turns out being unable to produce goodquality results even on the data it was trained from. This is known asunderfiting.
The result will be 0 in case of anoverfiting. That is, after training the algorithm isefficient on the data it was trained with, but ineffective with anything else.
A positive result greater than 0 if the algorithm showsgeneralization capabilitiesafterits training and can efficiently process data it had never seen previously. Obviously,the greater the number, the larger the generalization capability.
In a way, this function would define an “angle of some sort” which is illustrated in Figure 4by the problem space where the algorithm is efficient being narrower, the same, or larger,after training.
This function would have many parameters includingCXthe overall complexity of theproblem,SXthe size and representativity of the set of training examples relative to theproblem complexity,CAthe complexity of the AI model,SAthe size of the set of trainingexamples relative to the complexity of the AI model. There are very few known propertiesfor such function:
∀CA:∂L∂CX≤0,∂L∂SX≥0,∂L∂SA≥0,limSA→+∞L= 0,limSX→+∞L= 0(1)
Based on this first idea, let us now add the interfacing constraints that we have discussedpreviously:
Deep learning algorithms have fixed input layers which restricts what they canand cannot efficiently process. In our geometric representation, this gives hard limits suchas the ones shown in Figure 5(a) where no matter the quality of the algorithm, the learningis restricted by the narrow interfacing possibilities.
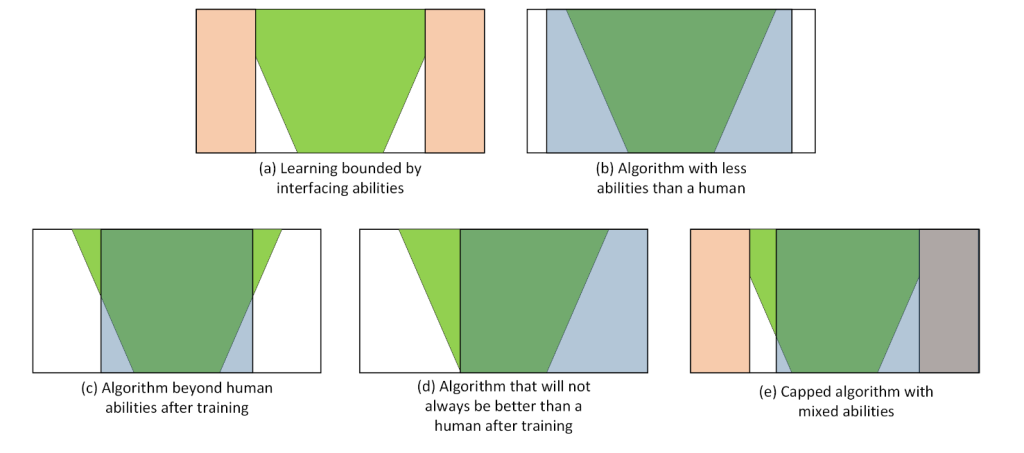
Figure 5: Geometric representation of different scenarios: The bottom and top lines of eachrectangle are the problem space. The learning process from bottom to top isin green, the hard interface boundaries are shown in red, and the boundaries ofreasonable human efficiency are in blue.
If we keep looking at Figure 5, we see a couple of other useful examples to understandthe strengths and limits of AI methods. In this Figure, we show in blue the boundaries ofreasonable human efficiencyover the same application domain than the algorithm. Pleasenote that the algorithm being outside of thereasonable human efficiencyzone does notnecessary mean that it is smarter. Indeed, many of the examples outside of this zone maywell be non-sensical, and there is no benefit in having the algorithm able to process them.
The goal of many Machine learning algorithms and AI is to be as effective or moreeffective than humans, and to do so with minimal training efforts. This would mean havinga narrow number of examples compared with the global human efficiency area to train thealgorithm, and an equal or larger efficiency of the AI after the training. This ideal scenariois shown in Figure 5(c) where the green area is narrower than the blue one at the bottom ofthe rectangle, but larger at the top. This also impliesL(CX, SX, CA, SA)>0 as a necessary,but not sufficient condition. Indeed, Figure 5(b) shows the very common example wheredespite having good learning properties, the AI remains less versatile and efficient than ahuman on a given domain after its training. Figures 5(d) and 5(e) show two other likelyscenarios: In the first one the AI exceeds human capabilities for some part of the domainproblem, but remains inferior in others. In the second one (which is even more common),we have the same phenomenon with an additional area of human efficiency which will neverbe reached by the AI because of its interface limitations.
Likewise, we have seen with large language models, that they require humongous amountsof data crawled from the internet and that they do not even guarantee good results. Bothfamilies of algorithms tackle this issue by having AI agents training with or against oneanother to further improve their performance in a process called adversarial learning thatwe have presented already. This process makes it possible to have, not one, but severalrounds of stacked training with the same AI architecture. If such AI is good enough atthe early stage (it has a positive learning angle), it will lead to proficiency in a potentiallylarger number of training examples after each iteration of the training, which can be usedto further improve the AI performances. We have seen how strong this process of stackedreinforcement learning and adversarial learning can be for gaming AI and large languagemodels. It is part of what has misled some into thinking that such process may lead to anexplosion of intelligence and ultimately to AGI.
In Figure 6, we show why this idea is false with 3 scenarios that take their explanationsfrom the properties of Equation (1):
1. In the first scenario from Figure 6(a), we see how the first pre-training starts with anarrow set of examples and a narrow yet positive angle which results in a much betterlearning angle with more examples at the second step of learning. Then because ofproperties (4) and (5), we know that for a fixed architecture and problem the learningangle is bound to go towards zero as the number of training examples increases. Thismeans, that regardless of the number of incremental learning iterations, improvementwill decrease and stop at some point.
2. Scenario 6(b) shows that we can’t even be sure that there will be an increase inlearning rate at all between the different learning steps. It is just as likely to get anever decreasing angle towards 0.
3. Finally, Figure 6(c) shows a last scenario where, regardless of the learning angle, itis the interface limitations of the algorithms which will stop the progress of the AIbefore it reaches its sample size limits.
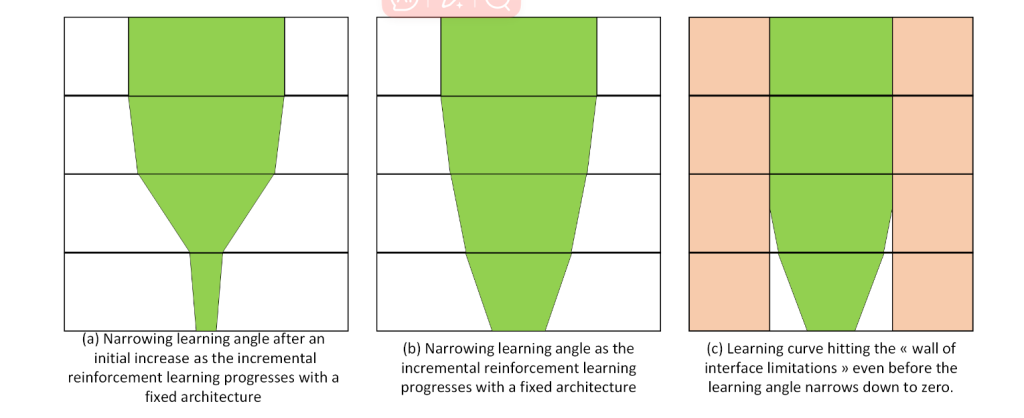
Figure 6: Geometric representation of different scenarios for stacked reinforcement learning:The bottom and top lines of each rectangle are the problem space. The learningprocess from bottom to top is in green, and the hard interface boundaries areshown in red.
While it is tempting to say that all it takes to remove these limits is to change thealgorithm architecture or input layers between training phases, we remind our reader thatthis is not that easy:
Even though knowledge acquired during the training process with an earlier architec-ture could be re-used, any architecture modification will result in a new network thathas to be re-trained from scratch. In other words: back to the first phase of training.
Modifying the input interfaces will result not only in having to retrain the AI fromscratch, but also in having to redefine training samples entirely.
4. Conclusion
4.1 LimitationsIn
this paper, we have studied several aspects that AI would need to achieve to becomewhat an AGI, and how current state of the art systems are both coming close to some ofthem, but also falling short for many of these aspects: The idea of beinggeneraland ableto tackle a wide variety of problems by contrast to a narrow range of problems, the notionsof adaptability and creativity, common-sense and basic reasoning abilities, and finally longterm memory.
Through 3 different types of AIs (AIs for games, generative artistic AIs and personalassistant), we have seen how each family has modern AI that seems to check several of the previously mentioned criteria: Gaming AIs have creative and reasoning abilities as well aslong term memory abilities that far surpass these of humans. Generative AIs are also ableto display creative abilities that result in new and unique pieces of art. And finally, personalassistant AIs based on large language models have shown long term memory, adaptability,creativity, common sense and basic reasoning abilities, as well as being quite versatile inhow they can assist humans.
However, we have also discussed the limits of these systems, and how what appears tolook like intelligence is sometimes an illusion made possible by the vast amounts of dataingested by these systems:
First, none of these systems is nowhere near being generic. While they are somewhatmore versatile than their predecessors, they remain limited to a narrow range of tasks:the fact that we have 3 categories of AIs discussed in this paper is proof enough ofthe lack of general purpose.
While assistant AIs appear to have reasoning and common sense abilities, they fail ona very regular basis to solve very simple problems, which shows that this illusion ofreasoning and common sense is mainly due to brute force learning. The same couldbe said of gaming AIs that play moves that are difficult to explain for a humans, butsometimes fail to see that the game is over and they have lost in situations where itwould be impossible to miss for a human.
The idea of creativity is very subjective and difficult to evaluate, even for humans. Wecould argue that most of what appears to be creative with these systems is merely thestatistical result of very long adversarial learning sessions with a bit of randomnesshere and there. And what to say about the hallucinations that LLMs systems havewhen they make up things because they have to answer something ? Is it creativity,or a proof of stupidity ?
Finally, we have seen that the adaptability and genericity of these systems is severelyhindered by the neural network architectures that power them: They are limitedin terms of how they can interface with the world, and their ability to evolve isconstrained by an architecture that needs to be retrained if it is modified.
We have also shown that this same architecture currently prevents the explosion ofintelligence, thesingularitythat some scientists from fields outside of artificial intel-ligence appear to fear.
Some scientists even go as far as saying that any illusion of emergent abilities in the latestversions of these systems (that is LLMs) can easily be debunked with the right statisticaltools and enough time (Schaeffer, Miranda, & Koyejo, 2023).
In short, we can say that despite undeniable and very impressive progresses, current AIssystems are very far from achieving AGI. We could even argue that they are not really inthe right direction because of the limitations imposed by neural network based architecturesin terms of volumes of data required to train them, interfacing constraints, lack of symboliclearning abilities and how these models are trained.
4.2 Challenges, Dangers and Opportunities
Being far from AGI does not mean that these systems and their future iterations won’thave a major impact on our society. While they are not AGI, these systems have provento be better and faster than humans in several key tasks: Deep fakes are already a majorsource of both amusement and disinformation at the same time. Large language models,which are the current trend, will most likely destroy a large number of assistant and whitecollar creative jobs, as well as call center jobs (such as customer services) in the coming fewmonths (Zarifhonarvar, 2023). Another example of potential disruption that these AIs maycause was highlighted during the recent writers and actors strike in Hollywood (Dalton &{The Associated Press}, 2023) with -among other things- the former fearing replacementby ChatGPT to write the scenarios of series to come, and the latter fearing the use ofGenerative AIs to use their younger image and voice without control for an infinite amountof time.
On the other hand, they will also make knowledge easily available and summarized toanyone with an internet connection. These AIs will also make basic programming languagesa lot easier and less time consuming. Likewise, they will be invaluable for translationand sumarization tasks, as well as for bibliographic works. While creative jobs such asprogrammers, writers, artists and assistants may see them as rivals and dangers, these AIsmay well prove to be valuable helpers rather than relentless and cheap labor replacement.There may also be job creations dedicated to cutting complex problems into simple onesthat these models can understand and fit within their limited input interfaces to achievethe best possible results.
However, due to the way they are trained, their nature as black box neural networks(whose answers are difficult to explain), and their tendency to have hallucination, there willbe real challenges around assessing the reliability of these models, especially large languagemodels (Liu et al., 2023). Indeed, the correct use of these tools may prove difficult for usersunaware of such issues, and that these systems are not the perfect oracles we often depictthem to be. They tell you (or write the piece of code) that they think you want to see, ratherthan a correct answer. This may lead to a large number of legal issues regarding who shouldbe responsible when one of these system will fail: The designers of the AI ? The peoplewho chose the data it was trained with ? The scientists tasked with the impossible missionof assessing the system reliability and putting an overlay of safeguards ? The company orfinal user of the trained system ?
Furthermore, when it comes to both large language models and artistic AIs, since theyproduce their answer (image, video or text) based on large datasets they have learned,copyright questions may arise due to some answers being full, partial or piece by piececopy-past of existing texts, codes and images that might be copyrighted. This may beparticularly challenging with most companies keeping their training data and processessecretive, and the data being impossible to guess once these algorithms are trained.
It is also easy to see how modern warfare could use systems similar to the gaming AIsdiscussed in this paper. It is hard to tell if this is a good or a bad thing, but countrieswithout them will be at a severe disadvantage. Furthermore, we should also be wary of thelimits discussed for these systems and what the consequences of the so-calledhallucinationsand other strange behaviors out of the regular scope would mean in the context of AIs being generalized in health systems, or for AI facing one another on financial markets. To thisday, it is impossible to tell.
Finally, since these systems can replace humans for many basics tasks such as drawing,programming, translation, computation, summarizing of documents, etc; we may wonderwhat could happen to a society where nobody practices basic skills anymore since AIs cando it better and faster. Indeed, while it may seem convenient, many of these basics skillsare also a necessary basis (hence their name) to learn more complex skills and tasks that AIcannot (or not yet) do. As such, and given the lack of real creativity of these systems, theremight also be a technological stagnation risk when they will have reached their limits as wehave discussed them in this paper, and when there might be no human skilled enough leftto feed them with higher level knowledge or skills due to an erosion of basic skills knowledgein the scientific population.
We may therefore conclude that the danger with currently emerging AI systems does notlie in their supposed intelligence, but on their short-comings as well as wrongly using them:It is difficult to predict the consequence of such systems -deployed on a global scale- reachingtheir limits and being used in ways that we either did not expect, or that -by design- theysimply cannot handle. There is also a major issue with the reliability of the results theyproduce: While they do fine in most cases, how do we detect the cases where they don’t? Furthermore, there are legal aspects both in terms of responsibility, but also in termsof copyrights and image rights due to their answers being produced from existing contentthey absorbed during their training which will need to be considered. Finally, we maycome back to the question of delegating too much to these systems, this time not becauseof the reliability risk, or the risk of job destruction, or not even the environmental cost ofthese systems (which we have not discussed in this paper), but because of the unknownconsequences of delegating to many basic tasks to machines and the risk of mass stagnationthat may occur.

