MLPerf training tests put Nvidia ahead, Intel close, and Google well behind

The leading public apples-to-apples test for computer systems’ ability to train machine-learning neural networks has fully entered the generative AI era. Earlier this year, MLPerf added a test for training large language models (LLM), GPT-3 in particular. This month it adds Stable Diffusion, a text-to-image generator. Computers powered by Intel and Nvidia took on the new benchmark. And the rivals continued their earlier battle in training GPT-3, where they were joined this go-around by Google.
All three devoted huge systems to the task—Nvidia’s 10,000-GPU supercomputer was the largest ever tested—and that size is necessary in generative AI. Even Nvidia’s largest system would have taken eight days of work to fully complete its LLM job.
Overall, 19 companies and institutions submitted more than 200 results, which showed a 2.8-fold performance boost over the past five months, and a 49-fold boost since MLPerf began five years ago.
Nvidia, Microsoft test 10,752-GPU monsters
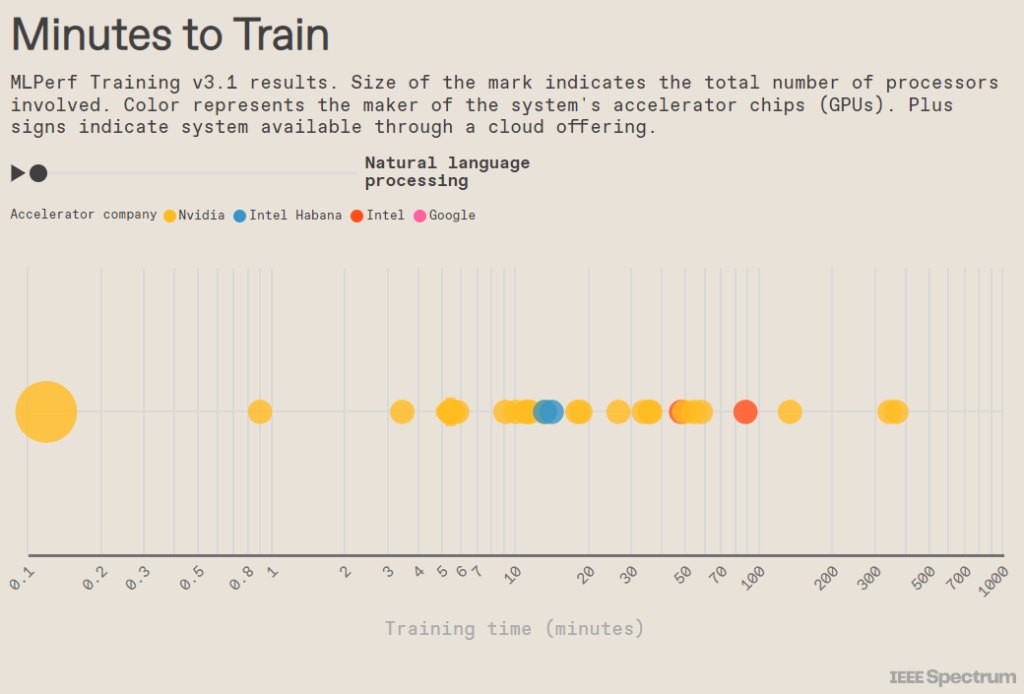
Nvidia continued to dominate the MLPerf benchmarks with systems made from its H100 GPUs. But the results from Eos, the company’s new 10,752-GPU AI supercomputer, were the cherry on top. Bending all those GPUsto the task of the GPT-3 training benchmark, Eos had the job done in just under 4 minutes. Microsoft’s cloud computing arm, Azure, tested a system of the exact same size and were behind Eos by mere seconds. (Azure powers GitHub’s coding assistant CoPilot and OpenAI’s ChatGPT.)
Eos’s GPUs are capable of an aggregate 42.6 billion billion floating-point operations per second (exaflops). And they are bound together with interconnects—Nvidia’s Quantum-2 Infiniband—that sling 1.1 million billion bytes per second. “Some of these speeds and feeds are mind-blowing,” says Dave Salvatore, Nvidia’s director of AI benchmarking and cloud computing. “This is an incredibly capable machine.”
Eos triples the number of H100 GPUs that have been bound into a single machine. That threefold increase achieved a 2.8-fold performance improvement, or 93 percent scaling efficiency. Efficient scaling is key to continued improvement of generative AI, which has been growing tenfold every year.
The GPT-3 benchmark Eos tackled is not a complete training of GPT-3, because MLPerf wanted it to be within reach of many companies. Instead, it involves training the system to a certain checkpoint that proves the training would have reached the needed accuracy given enough time. And these trainings do take time. Extrapolating from Eos’s 4 minutes means it would take eight days to complete the training, and that’s on what might be the most powerful AI supercomputer yet built. A computer of more reasonable size—512 H100s—would take four months.
Intel continues to close in
Intel submitted results for systems using the Gaudi 2 accelerator chip and for those that had no accelerator at all, relying on only its fourth-generation Xeon CPU. The big change from the last set of training benchmarks was that the company had enabled Gaudi 2’s 8-bit floating-point (FP8) capabilities. The use of lower precision numbers, such as FP8, has been responsible for most of the improvement in GPU performance in last 10 years. The use of FP8 in parts of GPT-3 and other transformer neural networks where their low precision won’t affect accuracy has already showed its value in Nvidia’s H100 results. Now Gaudi 2 is seeing the boost.
“We projected a 90 percent gain” from switching on FP8, says Eitan Medina, chief operating officer at Intel’s Habana Labs. “We delivered more than what was promised—a 103 percent reduction in time-to-train for a 384-accelerator cluster.”
That new result puts the Gaudi 2 system at a little less than one-third the speed of an Nvidia system on a per-chip basis and three times as fast as Google’s TPUv5e. On the new image-generation benchmark, Gaudi 2 was also about half the H100’s speed. GPT-3 was the only benchmark FP8 enabled for this round, but Medina says his team is working on switching it on for others now.
Medina continued to make the case that Gaudi 2 has a significantly lower price to the H100, and so it has an advantage on a combined metric of price and performance. Medina expects the advantage will grow with the next generation of Intel accelerator chip, Gaudi 3. That chip will be in volume production in 2024 and will be built using the same semiconductor manufacturing process as the Nvidia H100.
Separately, Intel submitted results for systems based only on CPUs, again showing training times between minutes and hours for several benchmarks. Beyond the MLPerf benchmarks, Intel also shared some data showing that a 4-node Xeon system, whose chips include the AMX matrix engine, can fine-tune the Stable Diffusion image generator in less than 5 minutes. Fine-tuning takes an already trained neural network and specializes it toward a certain task. For example, Nvidia’s chip design AI is a fine-tuning of an existing large language model called NeMo.